Some time ago, we discussed the topic of artificial neural networks and took a closer look at the process of training such models. If you haven't had the chance to familiarize yourself with the topic yet or would like to refresh your knowledge, we invite you to read our articles from this series.
In those texts, it was mentioned that a common problem, particularly faced by small companies due to limited budgets, is the price of the training process. To conduct the training of a large neural network model, it is necessary to either have access to a cloud service where computations can be delegated (which may require purchasing an expensive package for large model architectures) or to physically possess powerful computing units (usually GPUs - graphical processing units, often referred to as "graphics cards"), the cost of which has also significantly increased over the last few years.
Neural Networks and GPU - Why?
The first question that may come to the reader's mind could be: "Why would I train a neural network on a graphics processor?" Indeed, such an approach may not seem intuitive at first glance - after all, the unit typically used for hardware-related computations is the central processing unit, CPU. However, the answer lies in the nature of the computations performed for training such a network - they are relatively simple operations that can be easily parallelized (at least within the scope of calculating parameters for one layer of the model).
While CPUs typically have only a few cores designed for fast execution of parallel computations but with access to a large (compared to GPU cores) cache memory, GPUs are equipped with many more cores, which - despite having less power and cache size - are usually sufficient for the computations used in the training process. After all, GPUs, or graphics processors, are designed to enhance image display on the screen - their operation involves simultaneously calculating color values for thousands of pixels to ensure smooth image rendering and animation. However, determining the color of a single pixel is computationally simple - hence, such an architectural solution has been applied in "graphics cards."
Cache Memory
We mentioned that CPUs have access to larger cache memory than GPUs. Now let's see into what type of memory it is, how it is used, and what’s its structure.
The purpose of cache memory is to facilitate and speed up the access of the processing unit to data frequently used by it. The assumption is simple - the more often the processor needs access to certain resources, the shorter the access time should be. Therefore, cache memory is organized into levels, usually referred to as L1, L2, L3 (and, rarely, L4). The lower the number, the "closer" the memory is to the processor, and the smaller its size. At this point, it is worth mentioning that in various computer architecture descriptions, one can encounter designations for memory levels up to L7 - this is sometimes used to denote RAM layers and even disk memory. However, the principle remains unchanged - the higher the number, the longer the data access time compared to the previous levels, and usually - the larger the memory size.
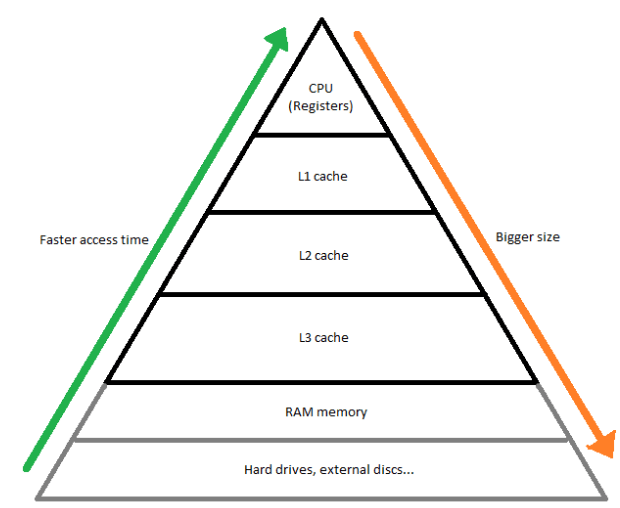
Fig. 1: Memory Characteristics
Now that we know the characteristics of GPU and CPU, we can infer why the main processor needs more space for fast access data - since it performs more complex operations, it often needs to remember intermediate operation results, of which there can be many. Furthermore, CPUs more frequently switch tasks (to achieve the effect of "parallel" execution of multiple tasks and to handle various types of hardware interruptions, such as user input), so they need a place where currently executed tasks can be "temporarily" stored and immediately resumed in a moment. Instructions for processors are also passed through cache memory - and those reaching the CPU are more diverse and usually more numerous compared o those for GPUs.
Below is a comparison of individual properties of CPU and GPU:
|
Aspect |
CPU |
GPU |
|
Number of cores |
Several dozen |
Thousands - tens of thousands |
|
Power of a single core |
Large |
Small |
|
Cache memory size |
3-4 levels, larger |
2-3 levels, smaller |
|
Dedicated vs shared memory levels per core |
Usually, cores have 3 dedicated cache levels (separate L1-L3 for each core). |
Usually, cores have only 1 dedicated level, the rest are shared (only L1 separate for each core). |
|
Example of application |
Operations requiring frequent context switching, complex single computations. |
Highly parallel operations, not requiring complex computations. |
It is worth noting that neural network training can be conducted using only CPU - however, it will typically proceed several dozen, several hundred times slower.
At this point, it is worth mentioning that to effectively utilize the capabilities offered by graphics processors, training must be appropriately configured. In the case of GPUs produced by NVIDIA, the CUDA framework is offered, which (after installation) allows for setting the appropriate hardware configuration. CUDA can be used from certain programming languages, such as Python 3 or C++, which makes preparing training in an optimal way way easier. Additionally, CUDA offers the possibility of splitting the training among several GPUs to make training of really large models more efficient.
But what if the model is so huge that it cannot even be trained in its entirety? In such a case, such a network can be divided among several computational nodes (usually division occurs between model layers) and rules for communication between them can be established - however, these are really complicated issues that most companies not focused on developing artificial intelligence as their main goal will not have to worry about in the near future.
Summary
To significantly accelerate the training of complex neural networks, it is worth leveraging the capabilities offered by graphics processing units - although they were not created for this purpose, they have proven to be a significant facilitation for machine learning engineers. However, it is important to carefully consider the configuration of such training in order to maximize the benefits from using more expensive hardware components.
That's all from us for today! Stay tuned for more machine learning content soon - we'll take a look at how to utilize the vast array of pre-trained models available on the internet for various general purposes to improve training for our specific goal. See you!