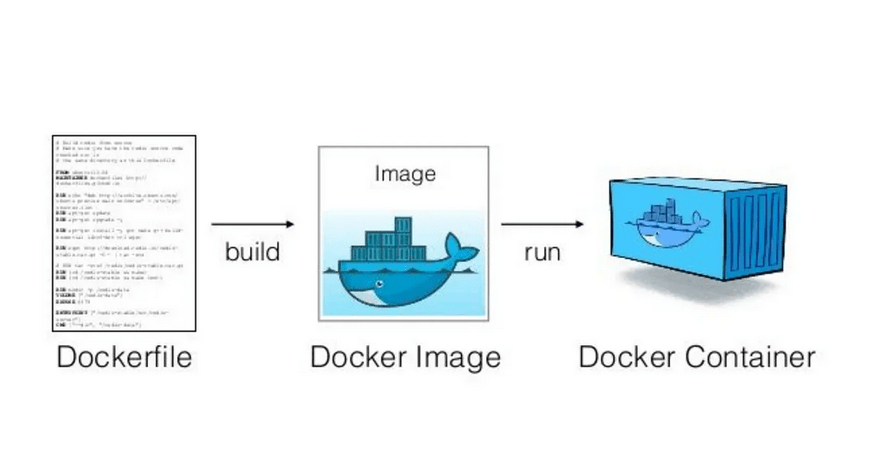
Docker – how to simplify running and deploying applications? (part 2)
In the article, we want to tell you about the details of Docker software and basic commands for its operation. We will also discuss the structure of the Dockerfile shown in the previous article and explain what volumes are and what they are used for.
Dockerfile commands
In the previous article, there was an example of a Dockerfile, but we didn’t discuss what each command does specifically.
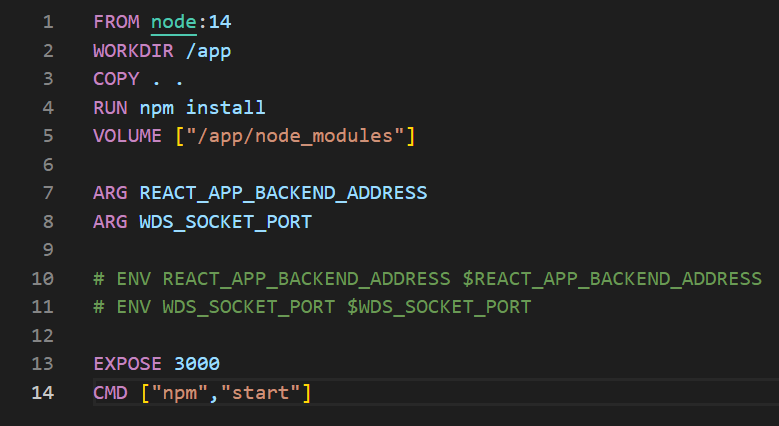
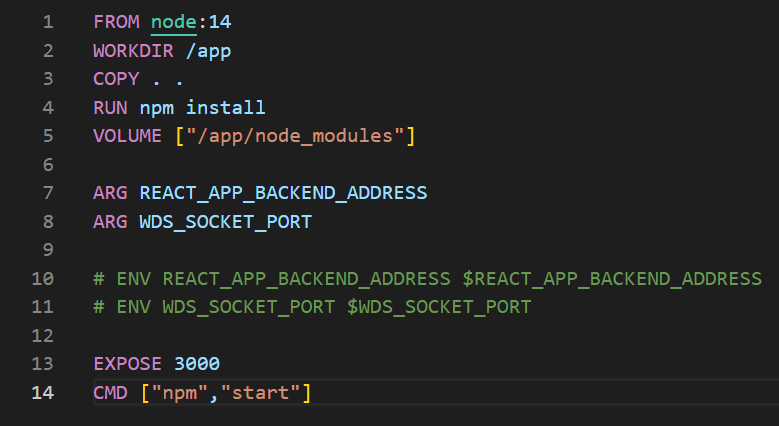
Picture 1: Sample Dockerfile running a JavaScript application.
FROM – We specify the base image on which we want to build our image. If it is not cached in the local repository, it will be downloaded from DockerHub.
WORKDIR – Changes the working directory inside the container (by default it is “/”). If the folder does not exist (like the /app folder here), it will be created. Using this command, and then referencing relatively is a good practice as opposed to providing specific absolute paths.
COPY – We specify which files should be copied from the outside (from our computer) into the image. The symbol “.” denotes the folder we are currently working in.
Syntax:
COPY <SRC_FROM_HOST> <DST_INTO_IMAGE>
It is also to use:
COPY . .
EXPOSE – Contrary to popular belief, this command does not expose the port outside the container (to the host system), nor does it expose the port to other containers (the port is available by default). This command is mainly used for documentation, although the ‘docker run’ command with the -P flag exposes the port specified in EXPOSE to the host system.
RUN – This command runs a command during image building. Here, in the case of “RUN npm install..”, we install dependencies that should be included with the image BEFORE starting the container itself.
CMD – This command will only be executed when the container starts. Here, with the “npm start” command, we launch the application, which should be done during startup. If we use “RUN npm start” in the Dockerfile, our image will not be built.There can only be one CMD command for each Dockerfile. If you do not specify CMD, Docker will try to find the CMD of the parent image (the one with FROM), and if it does not find it, it will throw an error.
Using these basic commands, we can set up the simplest application in any technology supported by Docker. Larger and more complicated applications often require more
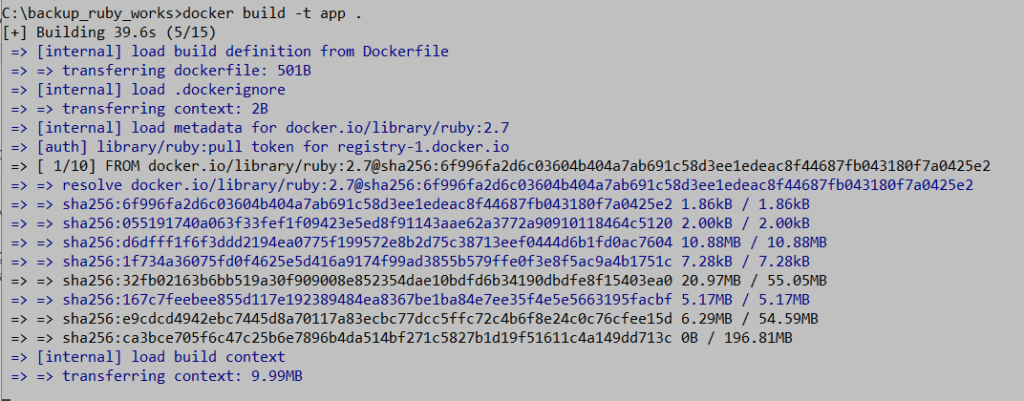
Picture 2: Building process of an image tagged as “app”.
To see the built image, we can use the “docker images” command, and if we want to examine the contents of the image in detail, we can use the “docker image inspect” command, which shows us the layers built corresponding to each command in the Dockerfile. The mechanism of calculating a checksum and using it to mark layers for caching and memory usage optimization.

Picture 3: Output of the ‘docker image inspect’ command showing the layers resulting from the Dockerfile commands.
In the context of subsequent layers and commands in the Dockerfile, it is worth mentioning how to efficiently use Docker’s cache. Commands that can often change the image hash, such as COPY . . (copying code), should be placed as late as possible in the Dockerfile so that a code change does not imply a change in the hash of constant layers. If you put COPY at the beginning, then commands like apt update or apt install will be executed again with each code change.
Sharing the image
We need to ask ourselves how we distribute our application to others. The answer is not obvious because we can do it in two ways. The first is to share the Dockerfile and dependencies (code) that are included in the image. The second is to use an image repository to distribute the application. In Docker, like in version control systems, there is the concept of a local and remote repository. Dockerhub is the official public version of this mechanism where you can store images of your created applications. It can be compared to Github but for Docker images.
Picture 4: Official MySQL database image. Source: Dockerhub.
On DockerHub, you can find images such as MySQL, Ubuntu, Alpine, Node, or Prestashop. These images are usually a lightweight Linux distribution with an integrated application such as MySQL or Node.js.
Types of Data
The data used in our applications can be classified in several ways. In the context of Docker, we can do it in the following way:
- Application data – stored in the image, such as our source code. Such data can be changed by rebuilding the image.
- Temporary data – stored in the container, and we don’t care about its persistence. Generated by the application or the container.
- Permanent data – data on which we cannot afford to lose. Stored in the container but kept on a mounted volume on the host system.
Volumes
A Docker Volume is a file system completely managed by the Docker platform, existing as a regular file or directory on the host where the data is persisted. The purpose of using Docker Volumes is to persist data outside of the container so that backups can be created and files can be moved between the container system and the host.
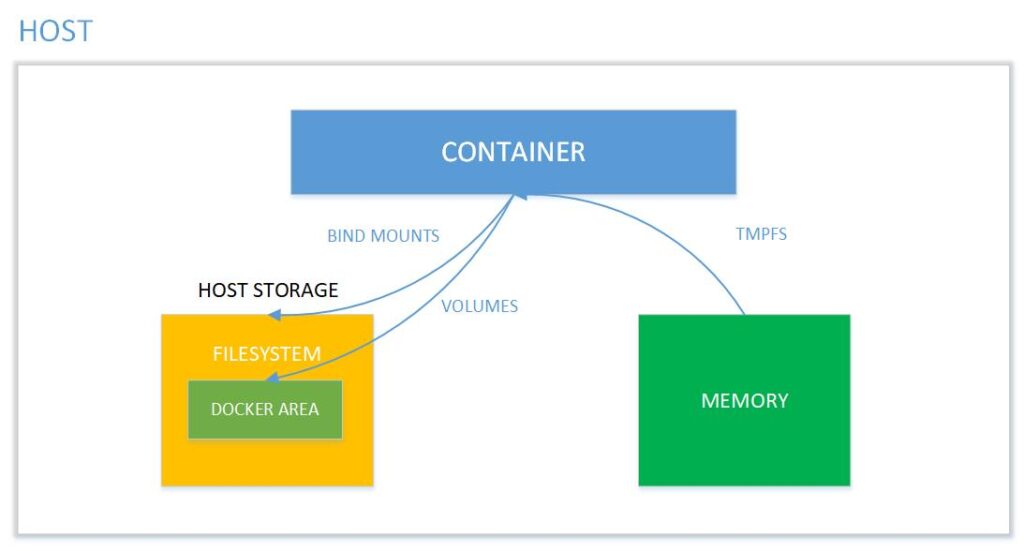
Picture 5: Memory mapping between the container and the host system Source: binarymaps.
Types of volumes:
- Anonymous – created automatically when using Dockerfile. They can also be created outside of Dockerfile using the “-v” parameter. Docker manages when they are created and destroyed. Such volumes are deleted along with the container when run with the –rm option.
- Named – named volumes are not deleted with the container. They are used for data that should be preserved but not directly edited. This type is more commonly used. Bind mounts – managed by the Docker user (more on this in the next part of our series)
Summary
Today we have learned the basic Dockerfile commands, how to distribute our containerized application, and the types of data and volumes that can be distinguished in Docker. In the next article, we will discuss more about bind mounts and the problems that may arise in this context. We will also explain what environment variables and the .dockerignore file are.
Source:
https://binarymaps.com/docker-storage/
https://pl.wikipedia.org/wiki/Wirtualizacja
https://www.atlassian.com/pl/microservices/cloud-computing/containers-vs-vms