Helm for the Second Time – Versioning and Rollbacks for Your Application
We describe how to perform an update and rollback in Helm, how to flexibly overwrite values, and discover what templates are and how they work.
 Author:
Author:Today, as Innokrea, we will talk a bit about what a distributed system is, what its properties are, and we will also see an example architecture of such a system. If you’re interested, we invite you to read on!
There are various definitions of what a distributed system actually is, ranging from formal and scientific to very practical ones. Some definitions indicate that a distributed system consists of many components or programs located on multiple nodes or computers. Others, however, not only emphasize distribution but also, for example, that a distributed system should appear to the user as a coherent system, and that there are various planes of distribution. However, certain attributes can be identified that characterize such software types, such as:
Of course, we haven’t listed all the characteristics here, but the above ones can give you some intuition about such systems. It should also be noted that not every distributed system fulfills all these characteristics.
The three most important planes on which applications can be distributed are: processing, control, and data. Depending on our requirements, we can manipulate the degree of distribution in these aspects. Processing distribution means that there are different computers connected to a network processing certain data, such as information retrieval or matrix multiplication. Nodes receive part of a certain task and expedite its execution if parallel data processing is possible. As for data, we can talk about their replication or so-called ‘data partitioning,’ which means storing them in different locations. An example here is databases, where problems with their replication and synchronization are properly resolved by database engines. As for control distribution, it involves transferring some control to another computer node. Examples could be a P2P network or a router, which makes routing decisions based on local information. Control over message passing is thus distributed. Let’s try to analyze the client-server architecture in terms of the above criteria:
Therefore, it can be said that the client-server architecture itself is neither a particularly distributed type of architecture nor centralized. However, this analysis could be heavily modified for certain scenarios, which wouldn’t be unusual. Here, we provide a general outline of such a system, and how distributed it should be to make the system optimal remains at the discretion of the designer.
One of the most important characteristics that a distributed system should have is the best possible concealment of the fact that it operates on multiple nodes. Thanks to this, the system’s user can use it without worrying about technical details as if it were operating on a single station. There are different types of transparency, including:
Both in the academic and commercial worlds, various types of distribution are used due to much greater possibilities of horizontal scaling (where we increase the number of stations to achieve greater computing power). Vertical scaling has its serious limitations and becomes uneconomical above a certain level. Clusters and supercomputers are used for computationally intensive tasks such as language model training or weather modeling. There are special platforms for distributing tasks to multiple computing nodes like Apache Hadoop.
In this regard, we recommend a series of articles about supercomputers: https://www.innokrea.com/supercomputers/
As for data, any solutions for storing large amounts of data can be mentioned, such as Google’s Bigtable or Amazon’s DynamoDB. Data are distributed among multiple nodes, allowing for the storage of vast amounts of data for later processing or directly saving information generated from processing other data. Control distribution, on the other hand, is used in handling energy or environmental systems, where software components can make local decisions without the involvement of a central server.
Classic examples of distributed systems familiar to programmers also include microservices used by companies like Netflix.
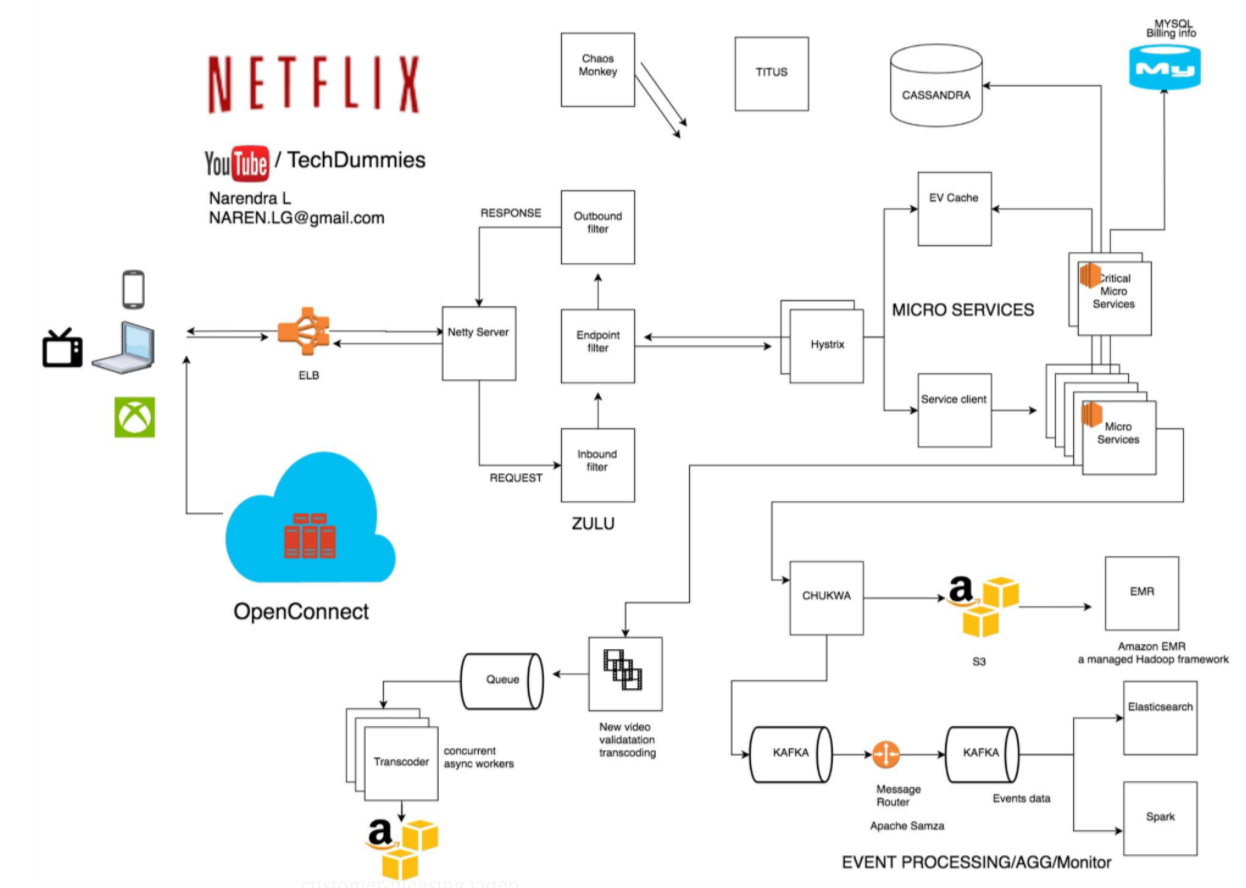
Figure 1 – Netflix Architecture Diagram [1]
Distributed systems are ubiquitous today, and we often use them without realizing that they are composed of many software components. The transparency of solutions contributes to user experiences, allowing them to benefit from fast and often reliable systems.
[1] https://elatov.github.io/2021/02/distributed-systems-design-netflix/

Helm for the Second Time – Versioning and Rollbacks for Your Application
We describe how to perform an update and rollback in Helm, how to flexibly overwrite values, and discover what templates are and how they work.
AdministrationInnovation
Helm – How to Simplify Kubernetes Management?
It's worth knowing! What is Helm, how to use it, and how does it make using a Kubernetes cluster easier?
AdministrationInnovation

INNOKREA at Greentech Festival 2025® – how we won the green heart of Berlin
What does the future hold for green technologies, and how does our platform fit into the concept of recommerce? We report on our participation in the Greentech Festival in Berlin – see what we brought back from this inspiring event!
EventsGreen IT