The use of neural networks in today’s world is so ubiquitous that it’s hard to find an industry sector where they aren’t utilized. However, despite access to countless studies, proper model preparation (even for seemingly simple tasks) is often a significant challenge. Today, as Innokrea, we would like to present to you some relatively simple techniques that can significantly improve the quality of trained neural networks. Enjoy reading!
Transfer Learning
Transfer Learning aims to shorten the convergence time of a model. The approach involves starting the process with the weights of a model previously trained on somewhat similar types of data, rather than training the neural network “from scratch,” i.e., with randomly initialized weights. Even if the task of such a network is clearly different from the one currently chosen, it’s better to begin with the weights of a previously trained model. The intuition behind this idea can be explained with the following everyday example: a medical student who can interpret ultrasound images should find it much easier to learn to interpret X-ray images than someone who has no knowledge of medical imaging.
In practice, transfer learning is implemented by downloading selected weights of pre-trained models from available repositories (known as model zoos) and initializing the architecture of a neural network based on them. Then, depending on whether the number of classes in the input model matches the desired number in the new task, it may be necessary to modify (or add) the output layer so that the number of neurons corresponds to the required number of classes. Another optional step may involve further modification of the model and the decision to freeze the layers of the architecture whose weights we do not want to change (usually, these are the layers closer to the model’s input). From this point on, training proceeds in a standard manner. Many contemporary libraries (e.g., Pytorch) enable very easy initialization of pre-trained models, providing their own model zoos. Typically, it’s sufficient to use one initialization parameter and provide the chosen version of weights (or choose the default parameter). For example, ResNet50(weights=pretrained) allows utilizing a pre-trained version of the ResNet50 architecture trained on the Imagenet dataset.
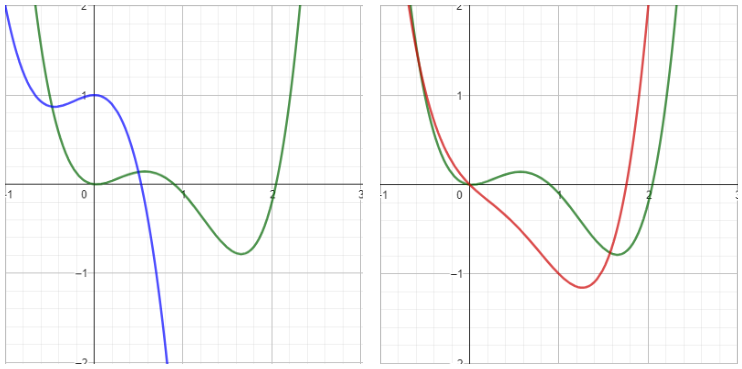
Fig. 1: The green function represents the target function to which the model should converge during training. On the left: the blue function symbolizes a model with randomly initialized weights; on the right: the red function imitates the use of pre-trained model weights. It can be assumed that iteratively improving the parameters of the red function to resemble the target function requires fewer iterations than it would with the blue function.
Domain Adaptation
A special category of transfer learning is called domain adaptation. It involves using a model that has already been trained but served a similar (or very similar) task. An example could be using a model that determines the malignancy of lung changes in CT scans from Hospital A and adapting it to classify lung changes in images taken at another hospital using different equipment. Another example of domain adaptation is adjusting this model to recognize malignancy of tumor changes in tomographic images but in the head area.
Training is Half the Success
Although the training phase presents developers with some challenges, with a bit of effort, one can often observe a gradual improvement in the model’s accuracy on the training set as the number of training epochs increases. Unfortunately, this is only half of the success – to simulate the model’s behavior on new, “unknown” data, validation must be applied. If you’re unsure about the purpose of validation in neural networks, we encourage you to read our article.
A common problem observed when attempting to train models is the lack of decrease (or increase) in the value of the loss function during the validation phase. There can be many reasons for this phenomenon, but among the most popular ones are: too small training set or too high learning rate. While addressing the latter issue is trivial, obtaining better results in the case of the former may be slightly more laborious. However, there is a well-known method for improving the model’s quality in such a situation: data augmentation.
Data Augmentation
When we suspect that we have too little data to conduct effective training, our first thought is usually not optimistic: I need to acquire more labeled samples! While sometimes this task can be as easy as spending five minutes searching the internet, it often tends to be much more complicated. In such situations, all kinds of data augmentation techniques come to the rescue, which involve using already available data with certain modifications. In the case of images, these techniques include rotation, flipping vertically or horizontally, changing the color palette, shifting… Of course, for each dataset, it’s necessary to consider which transformations will not introduce additional noise into the data or will not change the class of samples at all – for example, in the problem of classifying the skin color of individuals in images, excessive manipulation of the image brightness level could result in the class represented by the sample before augmentation no longer matching the resulting file, necessitating additional manual correction of the labels of all “new” data.

Fig. 2: An example of data augmentation. On the left side, the original image, class “flower”. On the right, four examples of transforming it to maintain the original class membership.
That’s all for today, see you soon!
Sources:
[1] https://www.image-net.org
[2] https://pytorch.org/vision/main/_modules/torchvision/models/resnet.html#resnet50



