How to Hack, How to Improve a Neural Network?

In the last article, we delved into the process of fine-tuning the parameters of a neural network during the training phase. Today, as Innokrea, we’ll tell you a few words about how to speed up and improve this training process. We’ll also show that although the accuracy of modern artificial neural network architectures can be even better than human accuracy (as of the date of writing this article), there are no infallible networks that can handle any task, even one that would be absurdly simple for a human. Join us for the read!
Millions of Annotated Samples?!
Undoubtedly, one of the significant barriers for many small and medium-sized corporations attempting to automate their business processes is the lack of access to large sets of labeled data. An even more significant issue arises when dealing with specialized data that only a qualified individual, such as a doctor, lawyer, or expert, can label. Creating such a dataset to serve as training data for the company’s specific needs not only requires a significant amount of time but also a considerable financial investment. Often, this is enough to discourage companies from implementing machine learning into their daily operations.
Active Learning – the Savior
Good news for those facing a similar problem: there are methods that allow you to label only a small part of the data from an unlabeled dataset and then train a model on this partially labeled dataset, achieving results very similar to a model trained on the entire labeled dataset. If it’s possible to label only 30% of the data instead of 100% and still get very similar results, it’s easy to see how this can translate into significant time and cost savings for a company!
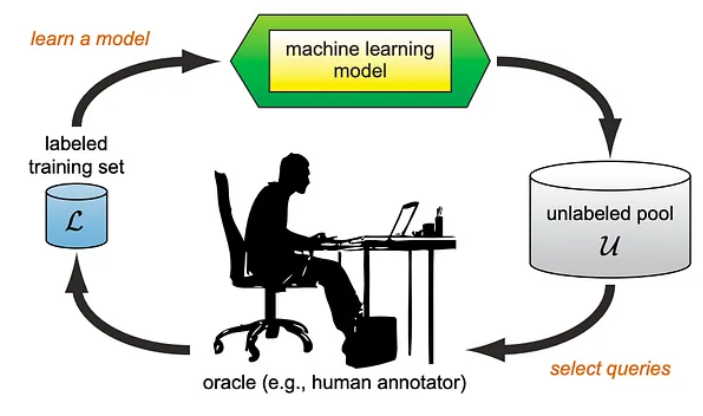
Fig. 1: Active Learning loop (src: Active Learning Literature Survey by Burr Settles) [1]
One way to achieve this is through the use of Active Learning. Active Learning is a method that, in general terms, focuses on selecting data points to label, which will be the most informative for the model. Active Learning usually occurs in rounds.
For example:
– We start by providing the model with a small portion of labeled data from the dataset (e.g., 5%).
– We train the model using this data.
– The model then performs a classification attempt on the remaining 95% of data.
– Based on the results of this attempt, we choose the next 5% of data to be labeled. The selection criteria can be, for example, how uncertain the model was in the most likely classes or how small the difference was between the two most probable classes.
To illustrate, consider the three-class classification results for two samples:
Sample A: [0.4, 0.55, 0.05]
Sample B: [0.25, 0.25, 0.5].
If we applied the first of the described selection methods, sample B would be chosen for manual labeling since the probability of the most likely class here is lower than for sample A (0.5 < 0.55).
In the second case, sample A would be manually labeled. The reason is that the difference between the probabilities of the two most probable classes is smaller than in the case of sample B (0.55-0.4 < 0.5-0.25).
This procedure, as described in the previous three steps, is repeated until a certain part of the dataset (e.g., 30%) is labeled or until the model is “confident enough” in classifying the remaining data (usually determined by a specific parameter, or more complex methods are applied).
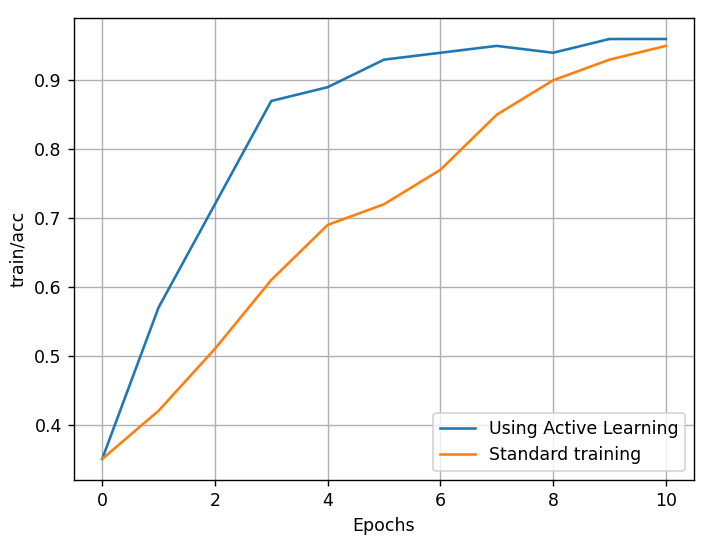
Fig. 2: Comparison of the learning rate of the model with active learning and without
Of course, this is not the only method that can significantly reduce the number of samples that need to be labeled in a dataset. Another interesting approach, for example, is to transform the samples into feature vectors (feature extracting), group them based on similarities into a certain number of groups (clustering), and then select representatives from these groups for manual labeling. After this labeling, the labels are propagated to the rest of the samples in that group.
Such methods are often referred to as human-in-the-loop machine learning.
Can You… Hack a Network?
To answer this question, let’s ask one question: what do you see in the right and left images?

Fig. 3: Two images
Yes, for a human, the answer is simple – it’s the same image.
In the case of a neural network, however, we can be very surprised!

Fig. 4: Neural network error after changing the color of one pixel in the image
Surprising? Very much so! It turns out that practically any neural network can be tricked this way – the human eye will not notice any difference. However, with the right transformation of a single pixel’s color or the application of a very slight mask to the image, the data in the neural network can be recognized in an entirely unpredictable way. We recommend exploring the following articles on this subject:
- One-pixel attack for fooling deep neural networks [2]
- Explaining and Harnessing Adversarial Examples [3]
With this note, we conclude our series of articles on neural networks. See you next week!
References:
[1] Burr Settles. Active Learning Literature Survey. Computer Sciences Technical Report 1648, University of Wisconsin–Madison. 2009
[2] https://arxiv.org/abs/1710.08864
[3] https://arxiv.org/abs/1412.6572



